Node.js 是运行在服务器上的 JavaScript,具备单线程、异步 IO、事件驱动等特性。之前对这些特性的理解只是通过一些博客,始终不得要领。最近读了朴灵的《深入浅出 Node.js》,对此有了更清晰明确的认识。
Node.js 运行示意图:
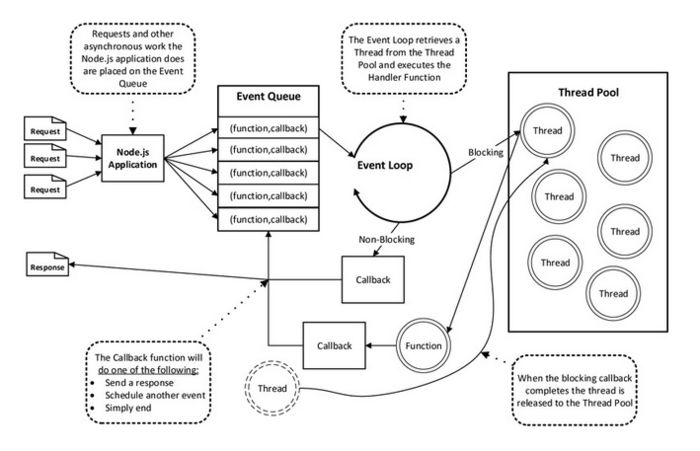
关于单线程
JavaScript 语言的一大特点就是单线程,也就是说,同一个时间只能做一件事。JavaScript 的单线程,与它最初的设计用途有关。作为浏览器脚本语言,JavaScript 的主要用途是与用户互动,以及操作 DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定 JavaScript 同时有两个线程,一个线程在某个 DOM 节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?
单线程串行执行的缺点在于性能,任意一个略慢的任务都会导致后续执行代码被阻塞。在计算机资源中,通常 IO 与 CPU 计算之间是可以并行进行的。但是同步的编程模型导致的问题是,IO 的进行会让后续任务等待,这造成资源不能被更好地利用。
我们时常提到 Node 是单线程的,这里的单线程仅仅只是 JavaScript 执行在单线程中罢了,Node 底层维护了线程池,来支持对 IO 任务进行异步调用,以此实现了高性能的服务器。无论是*nix还是Windows平台,内部完成 IO 任务的另有线程池。
事件驱动
在进程启动时,Node 会创建一个类似于 while (true) 的循环,叫做 Event Loop。每执行一次循环体的过程我们称为Tick。每个Tick的过程就是查看是否有事件待处理,如果有,就取出事件及其相关的回调函数,然后执行它们,这就是所谓的 事件驱动。
在每个Tick的过程中,如何判断是否有事件需要处理呢?这里必须要引入的概念是 观察者。每个事件循环中有一个或者多个观察者,而判断是否有事件要处理的过程就是向这些观察者询问是否有要处理的事件。
循环过程中,如果碰到异步 IO 调用,会将 IO 任务封装成 请求对象,由 Node 底层的 libuv 模块根据平台送入对应的 IO 线程池等待执行。
线程池中的 IO 操作调用完毕之后,会将获取的结果储存在请求对象的属性上,并将线程归还线程池,在下一轮Tick时,IO 观察者会检查是否有执行完的请求,如果存在,会将请求对象加入到 IO 观察者的队列中,然后将其当做事件处理。
需要强调一点的是,这里的 IO 不仅仅只限于磁盘文件的读写。*nix将计算机抽象了一番,磁盘文件、硬件、套接字等几乎所有计算机资源都被抽象为了文件
异步 IO
在听到 Node 的介绍时,我们时常会听到异步、非阻塞、回调、事件这些词语混合在一起推介出来,其中异步与非阻塞听起来似乎是同一回事。从实际效果而言,异步和非阻塞都达到了我们并行 IO 的目的。但是从计算机内核 IO 而言,异步 / 同步和阻塞 / 非阻塞实际上是两回事。
非阻塞 IO
操作系统内核对于 IO 只有两种方式:阻塞与非阻塞。在调用阻塞 IO 时,一定要等到系统内核层面完成所有操作后,调用才结束。以读取磁盘上的一段文件为例,系统内核在完成磁盘寻道、读取数据、复制数据到内存中之后,这个调用才结束。
阻塞 IO 造成 CPU 等待 IO,浪费等待时间,CPU 的处理能力不能得到充分利用。为了提高性能,内核提供了非阻塞 IO。非阻塞 IO 跟阻塞 IO 的差别为调用之后会立即返回。非阻塞 IO 返回之后,CPU 的时间片可以用来处理其他事务,此时的性能提升是明显的。
但非阻塞 IO 也存在一些问题。由于完整的 IO 并没有完成,立即返回的并不是业务层期望的数据,而仅仅是当前调用的状态。为了获取完整的数据,应用程序需要重复调用 IO 操作来确认是否完成。这种重复调用判断操作是否完成的技术叫做轮询,Linux 中的实现方式是 epoll。
轮询技术满足了非阻塞 IO 确保获取完整数据的需求,但是对于应用程序而言,它仍然只能算是一种同步。因为应用程序仍然需要等待 IO 完全返回,依旧花费了很多时间来等待。等待期间,CPU 要么用于遍历文件描述符的状态,要么用于休眠等待事件发生。结论是它不够好。
理想的异步 IO
尽管 epoll 已经利用了事件来降低 CPU 的耗用,但是休眠期间 CPU 几乎是闲置的,对于当前线程而言利用率不够。我们期望的完美的异步 IO 应该是应用程序发起非阻塞调用,无须通过遍历或者事件唤醒等方式轮询,可以直接处理下一个任务,只需在 IO 完成后通过信号或回调将数据传递给应用程序即可。
幸运的是,在 Linux 下存在这样一种方式,它原生提供的一种异步 IO 方式 (AIO) 就是通过信号或回调来传递数据的。但不幸的是,只有 Linux 下有,而且它还有缺陷:AIO 仅支持内核 IO 中的 O_DIRECT 方式读取,导致无法利用系统缓存。
现实的异步 IO
现实比理想要骨感一些,但是要达成异步 IO 的目标,并非难事。前面我们将场景限定在了单线程的状况下,多线程的方式会是另一番风景。通过让部分线程进行阻塞 IO 或者非阻塞 IO 加轮询技术来完成数据获取,让一个线程进行计算处理,通过线程之间的通信将 IO 得到的数据进行传递,这就轻松实现了异步 IO (尽管它是模拟的)。
由于 Windows 平台和 * nix 平台的差异,Node 提供了 libuv 作为抽象封装层,使得所有平台兼容性的判断都由这一层来完成,并保证上层的 Node 与下层的自定义线程池及 IOCP 之间各自独立。 Node 在编译期间会判断平台条件,选择性编译 unix 目录或是 win 目录下的源文件到目标程序中。
服务器模型变迁
从 “古” 到今,Web 服务器的架构已经历了几次变迁。服务器处理客户端请求的并发量,就是每个里程碑的见证。
石器时代:同步
最早的服务器,其执行模型是同步的,它的服务模式是一次只为一个请求服务,所有请求都得按次序等待服务。这意味除了当前的请求被处理外,其余请求都处于耽误的状态。它的处理能力相当低下,假设每次响应服务耗用的时间稳定为 N 秒,这类服务的 QPS 为 1/N。
这类架构如今已基本被淘汰,只在一些无并发要求的应用中存在。
青铜时代:复制进程
为了解决同步架构的并发问题,一个简单的改进是通过进程的复制同时服务更多的请求和用户。这样每个连接都需要一个进程来服务,即 100 个连接需要启动 100 个进程来进行服务,这是非常昂贵的代价。在进程复制的过程中,需要复制进程内部的状态,对于每个连接都进行这样的复制的话,相同的状态将会在内存中存在很多份,造成浪费。并且这个过程由于要复制较多的数据, 启动是较为缓慢的。
假设通过进行复制和预复制的方式搭建的服务器有资源的限制,且进程数上限为 M,那这类服务的 QPS 为 M/N。
白银时代:多线程
为了解决进程复制中的浪费问题,多线程被引入服务模型,让一个线程服务一个请求。线程相对进程的开销要小许多,并且线程之间可以共享数据,内存浪费的问题可以得到解决,并且利用线程池可以减少创建和销毁线程的开销。但是多线程所面临的并发问题只能说比多进程略好,因为每个线程都拥有自己独立的堆栈,这个堆栈都需要占用一定的内存空间。
另外,由于一个 CPU 核心在一个时刻只能做一件事情,操作系统只能通过将 CPU 切分为时间片的方法,让线程可以较为均匀地 使用 CPU 资源,但是操作系统内核在切换线程的同时也要切换线程的上下文,当线程数量过多时,时间将会被耗用在上下文切换中。所以在大并发量时,多线程结构还是无法做到强大的伸缩性。
如果忽略掉多线程上下文切换的开销,假设线程所占用的资源为进程的 1/L,受资源上限的 影响,它的 QPS 则为 M * L/N。
黄金时代:事件驱动
多线程的服务模型服役了很长一段时间,Apache 就是采用 多线程 / 多进程 模型实现的,当并发增长到上万时,内存耗用的问题将会暴露出来,这即是著名的 C10k 问题。
为了解决高并发问题,基于事件驱动的服务模型出现了,像 Node 与 Nginx 均是基于事件驱动的方式实现的,采用单线程避免了不必要的内存开销和上下文切换开销。由于所有处理都在单线程上进行,影响事件驱动服务模型性能的点在于 CPU 的计算能力,它的上限决定这类服务模型的性能上限,但它不受多进程或多线程模式中资源上限的影响,可伸缩性远比前两者高。
文档信息
- 本文作者:Ning Zhang
- 本文链接:https://sunsetroads.github.io/2020/01/18/node-eventloop/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)